A Spark DataFrame is an immutable tabular data structure that is the most common Structured API in Spark.
Spark execution hierarchy: Job > Stage > task Slot is not technically part of the hierarchy itself, but rather the resource threads that can be used for parallelization within a Spark application. Executor is not technically part of the hierarchy itself, but the process in the work node
Low number of executor is likely to experience delays due to garbage collection of a large DF
A partition is a collection of rows of data that fit on a single machine in a cluster.
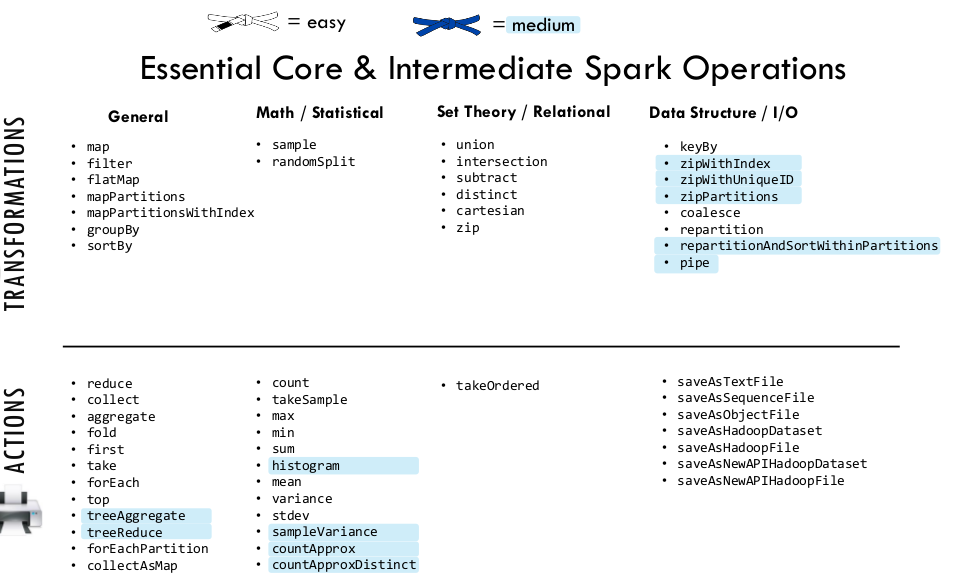
filter() is a narrow transformation along with select, cast, union, filter whereas distinct, groupBy, sort, join are wide and induces shuffles/exchanges
Garbage collection in JVM is about releasing memory of objects that are no longer used so that new objects can be created