Here’s an overview of the steps:
- Write DataFrame/Dataset/SQL Code.
- If valid code, Spark converts this to a Logical Plan.
- Spark transforms this Logical Plan to a Physical Plan, checking for optimizations alongthe way.
- Spark then executes this Physical Plan (RDD manipulations) on the cluster.
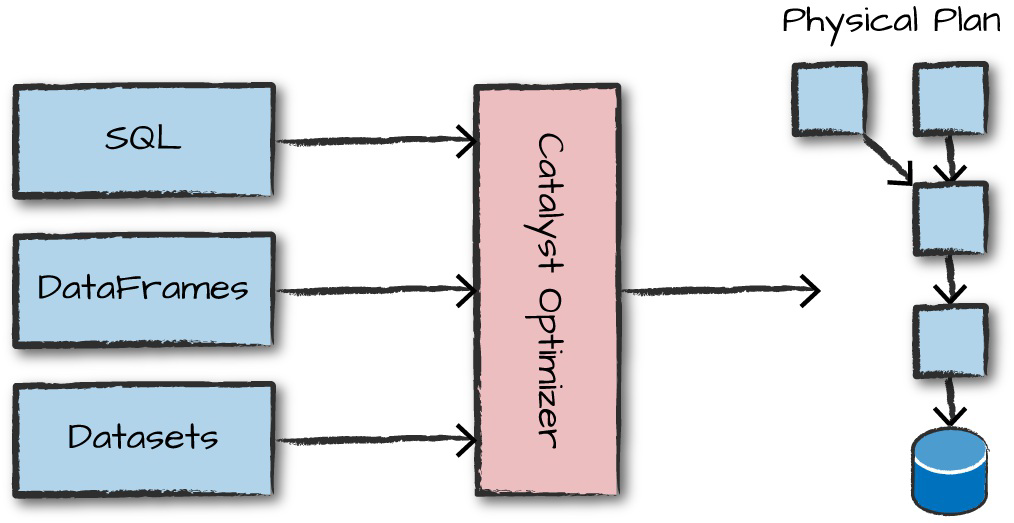
To execute code, we must write code. This code is then submitted to Spark either through the console or via a submitted job. This code then passes through the Catalyst Optimizer, which decides how the code should be executed and lays out a plan for doing so before, finally, the code is run and the result is returned to the user.
Logical planning (no driver/ executor involved)
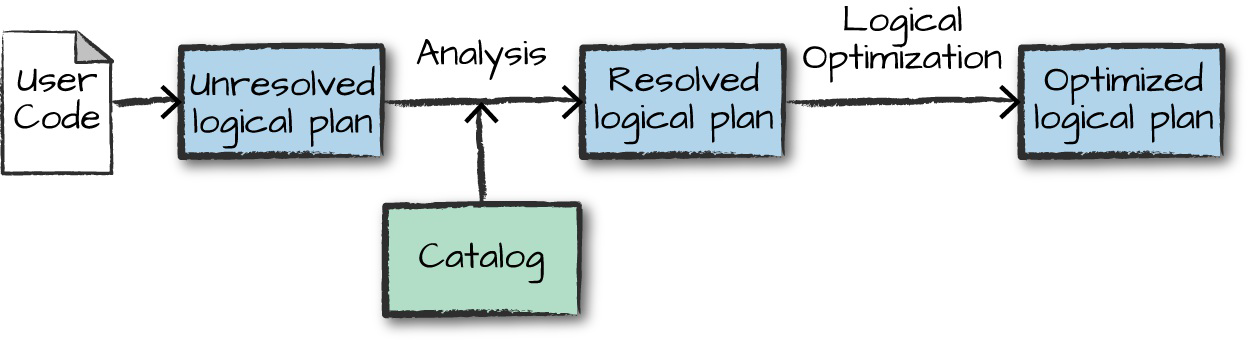 The first phase of execution is meant to take user code and convert it into a logical plan
The first phase of execution is meant to take user code and convert it into a logical plan
- only check the syntax errors (unresolved logical plan - validate the code)
- spark uses the catalog, a repository of all table and DataFrame information, to resolve columns and tables in the analyzer. The analyzer might reject the unresolved logical plan if the required table or column name does not exist in the catalog (resolved logical plan)
- If the analyzer can resolve it, the result is passed through the Catalyst Optimizer, a collection of rules that attempt to optimize the logical plan by pushing down predicates or selections (optimized logical plan)
Physical plan:
Physical planning compiles all structured API resulting in a series of RDDs and transformations.
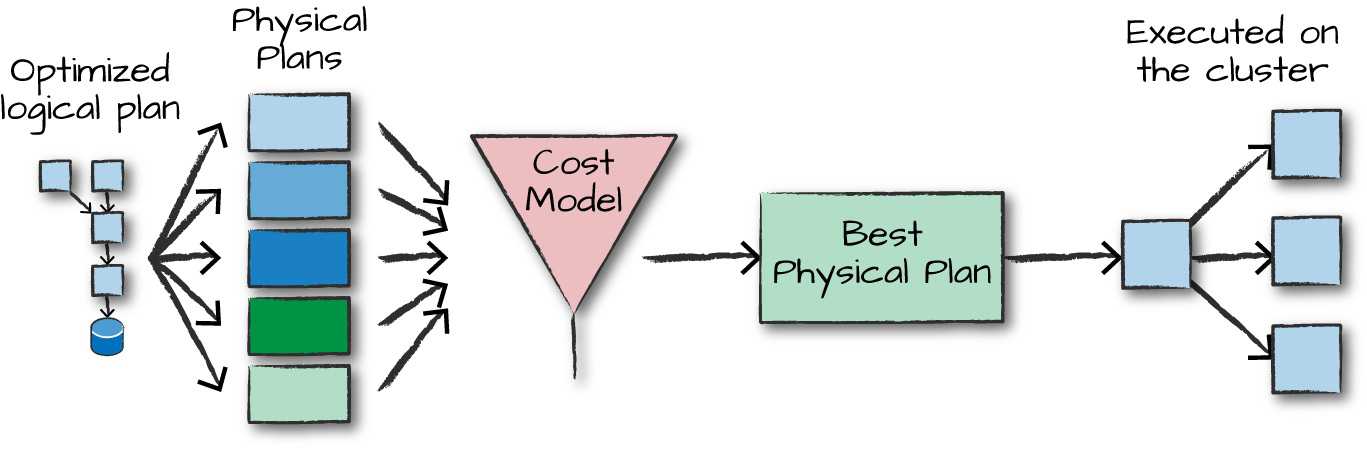
- generating different physical execution strategies and comparing them through a cost model
- pass through a cost model to evaluate the best physical plan based on physical attributes of a given table (e.,g. table size, partition)